程序的内存布局
在平坦的内存模型中,整个内存是一个统一的地址空间,用户可以使用一个32位的指针访问任意内存位置。但实际上内存仍然在不同的地址区间上有着不同的地位,例如,大多数操作系统都会将4GB的内存空间中的一部分挪给内核使用,应用程序无法直接访问这一段内存,这一部分内存地址被称为内核空间。在用户空间里,也有许多地址区间有特殊的地位,一般来讲,应用程序使用的内存空间里有如下“默认”的区域:
- 栈:栈用于维护函数调用的上下文。
- 堆:堆是用来容纳应用程序动态分配的内存区域。
- 可执行文件映像:存储可执行文件在内存里的映像。
- 保留区:对内存中受到保护而禁止访问的内存区域的总称。
下图是Linux进程典型的内存布局(内核2.4版本):
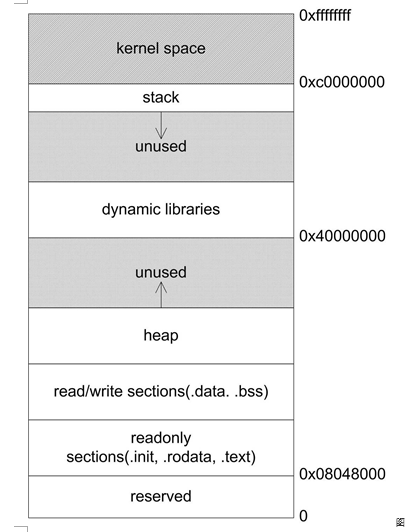 在图中,有一个区域叫:“动态链接库映射区”,这个区域用于映射装载的动态链接库。在Linux下,如果可执行文件依赖其他共享库,那么系统就会为它在从0x40000000开始的地址分配相应的空间,并将共享库载入到该空间。
在图中,有一个区域叫:“动态链接库映射区”,这个区域用于映射装载的动态链接库。在Linux下,如果可执行文件依赖其他共享库,那么系统就会为它在从0x40000000开始的地址分配相应的空间,并将共享库载入到该空间。
栈与调用惯例
什么是栈
栈保存了函数调用所需要维护的信息,被称为堆栈帧(Stack Frame)或活动记录(Activate Record)。堆栈帧包括以下内容:
- 函数的返回地址和参数。
- 临时变量:包括函数的非静态局部变量以及编译器自动生成的其他临时变量。
- 保存的上下文:包括在函数调用前后需要保持不变的寄存器。
在i386中,一个函数的活动记录用ebp和esp这两个寄存器划定范围。esp寄存器始终指向栈的顶部,同时也就指向了当前函数的活动记录的顶部。而相对的,ebp寄存器指向了函数活动记录的一个固定位置,ebp寄存器又被称为帧指针(Frame Pointer)。一个很常见的活动记录示例如图所示
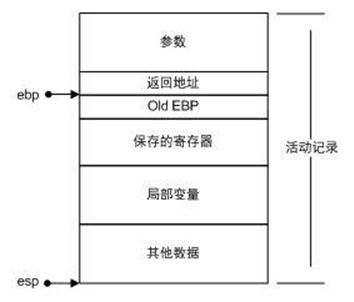 在参数之后的数据(包括参数)即是当前函数的活动记录。固定不变的ebp可以用来定位活动记录中的各个数据,它指向调用该函数前ebp的值,在函数返回时,ebp通过读取这个值恢复到调用前的值。函数调用的方式决定了活动记录的结构,i386下的函数总是这样调用的:
在参数之后的数据(包括参数)即是当前函数的活动记录。固定不变的ebp可以用来定位活动记录中的各个数据,它指向调用该函数前ebp的值,在函数返回时,ebp通过读取这个值恢复到调用前的值。函数调用的方式决定了活动记录的结构,i386下的函数总是这样调用的:
- 把所有或一部分参数压入栈中,如果有其他参数没有入栈,那么使用某些特定的寄存器传递。
- 把当前指令的下一条指令的地址压入栈中。
- 跳转到函数体执行。
其中第2步和第3步由指令call一起执行。跳转到函数体之后即开始执行函数,而i386函数体的“标准”开头是这样的(但也可以不一样):
- push ebp:把ebp压入栈中(称为old ebp)。
- mov ebp, esp:ebp = esp(这时ebp指向栈顶,而此时栈顶就是old ebp)。
- 【可选】sub esp, XXX:在栈上分配XXX字节的临时空间。
- 【可选】push XXX:如有必要,保存名为XXX寄存器(可重复多个)。
把ebp压入栈中,是为了在函数返回的时候便于恢复以前的ebp值。而之所以可能要保存一些寄存器,在于编译器可能要求某些寄存器在调用前后保持不变,那么函数就可以在调用开始时将这些寄存器的值压入栈中,在结束后再取出。不难想象,在函数返回时,所进行的“标准”结尾与“标准”开头正好相反:
- 【可选】pop XXX:如有必要,恢复保存过的寄存器(可重复多个)。
- mov esp, ebp:恢复ESP同时回收局部变量空间。
- pop ebp:从栈中恢复保存的ebp的值。
- ret:从栈中取得返回地址,并跳转到该位置。
调用惯例
调用惯例指函数调用的约定,包含以下内容:
- 函数参数的传递顺序和方式,方式指使用栈还是寄存器等,顺序指从左到右或反过来。
- 栈的维护方式,规定由调用者还是被调函数清理栈(将压入的参数弹出)。
- 名字修饰(Name-mangling)的策略,用于链接时区分不同的调用惯例。
C语言中存在多个调用惯例,默认使用cdecl。cdecl的惯例内容如下:
| 参数传递 | 出栈方 | 名字修饰 |
|---|---|---|
| 从右到左压栈 | 调用方 | 函数名前加1个下划线 |
_cdecl是非标准关键字,不同的编译器里有不同的写法,如gcc使用__attribute__((cdecl))。
举个例子,假设foo函数完整声明如下所示:
int _cdecl foo(int n, float m);
int main (){
foo(1,3);
return;
}
则实际操作如下图所示(参考前文描述):
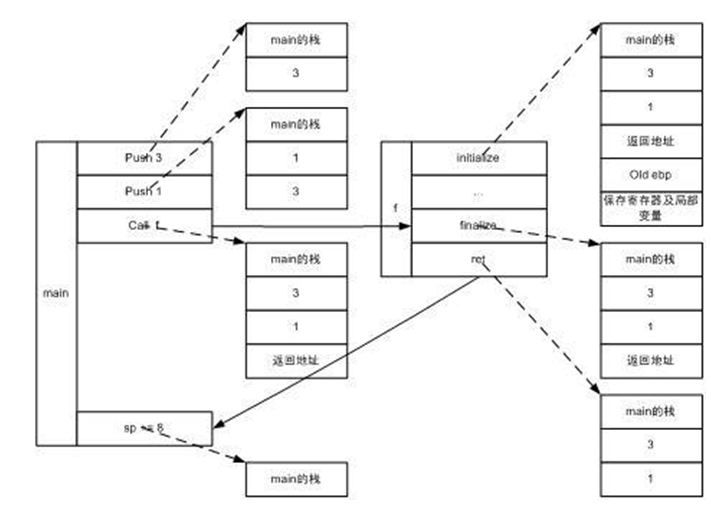
虚线指向该指令执行后的栈状态,实线表示程序的跳转。
多级调用栈布局:
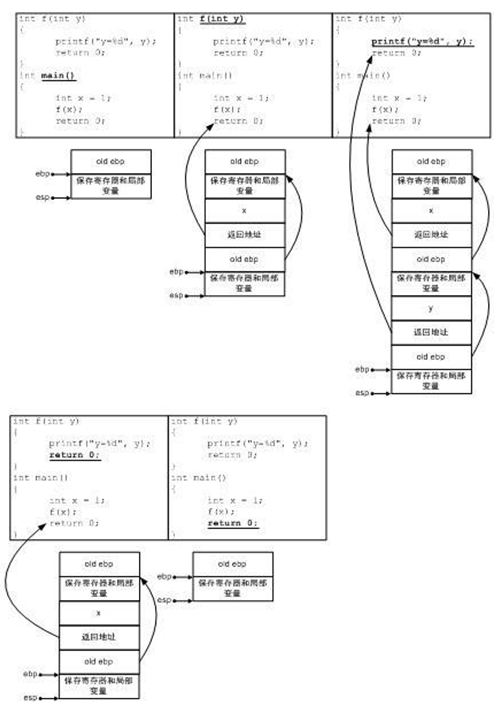
箭头表示地址的指向关系,而带下划线的代码表示当前执行的代码。
几种主要的调用惯例:
| 调用惯例 | 出栈方 | 参数传递 | 名字修饰 |
|---|---|---|---|
| cdecl | 函数调用方 | 从右到左压栈 | 下划线+ 函数名 |
| stdcall | 函数本身 | 从右到左压栈 | 下划线+函数名+@+参数的总字节数 |
| fastcall | 函数本身 | 头两个DWORD(4byte)类型或者占更少字节的参数被放入寄存器,剩下的参数从右到左压栈 | @+函数名+@+参数的总字节数 |
| pascal | 函数本身 | 从左到右压栈 | 较复杂,参见pascal文档 |
此外,不少编译器还提供一种称为naked call的调用惯例,这种调用惯例用在特殊的场合,其特点是编译器不产生任何保护寄存器的代码,故称为naked call。对于C++语言,以上几种调用惯例的名字修饰策略都有所改变,参考”目标文件中有什么”一文。最后,C++自己还有一种特殊的调用惯例,称为thiscall,专用于类成员函数的调用。其特点随编译器不同而不同,在VC里是this指针存放于ecx寄存器,参数从右到左压栈,而对于gcc,thiscall和cdecl完全一样,只是将this看作是函数的第一个参数。
函数返回值传递
返回值是函数与调用方交互的另一个渠道。前面的例子使用eax传递返回值,函数将返回值存储在eax中,返回后函数的调用方再读取eax。但eax只有4个字节, 对于返回5~8字节对象的情况,几乎所有的调用惯例都是采用eax和edx联合返回的方式进行的。eax返回低4字节,edx返回高4字节。而对于超过8字节的返回类型,用下面代码来研究:
typedef struct big_thing
{
char buf[128];
}big_thing;
big_thing return_test()
{
big_thing b;
b.buf[0] = 0;
return b;
}
int main()
{
big_thing n = return_test();
}
return_test返回128字节的结构,不可能直接用eax传递。反汇编main函数(MSVC9):
big_thing n = return_test();
00411498 lea eax,[ebp-1D0h]
0041149E push eax
0041149F call _return_test
004114A4 add esp,4
004114A7 mov ecx,20h
004114AC mov esi,eax
004114AE lea edi,[ebp-88h]
004114B4 rep movs dword ptr es:[edi],dword ptr [esi]
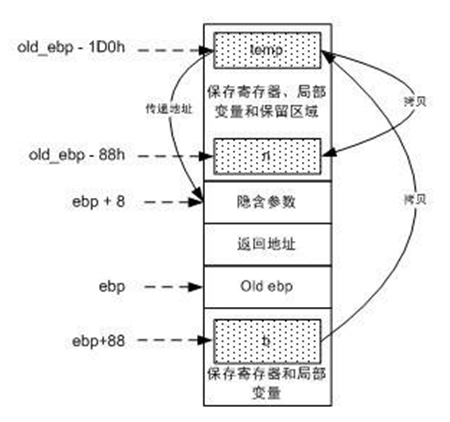
第二行 00411498 lea eax,[ebp-1D0h],将栈上的一个地址(ebp-1D0h)存储在eax里。
下一行:push eax 将这个地址压入栈中,然后就紧接着调用return_test函数。
这从形式上无疑是将数据ebp-1D0h作为参数传入return_test函数,然而return_test是没有参数的,因此这是个“隐含参数”。即return_test的原型实际是:
big_thing return_test(void* addr);
这段汇编最后4行是一个整体,可以想象在函数返回之后,函数的调用方需要获取函数的返回对象并对n赋值。rep movs是一个复合指令,它的大致意义是重复movs指令直到ecx寄存器为0。于是“rep movs a, b”的意思就是将b指向位置上的若干个双字(4字节)拷贝到由a指向的位置上,拷贝双字的个数由ecx指定,实际上这句复合指令的含义相当于memcpy(a, b, ecx * 4)。所以说,最后4行的含义相当于:
memcpy(ebp-88h, eax, 0x20 * 4)
即将eax指向位置上的0x20个双字拷贝到ebp-88h的位置上。毫无疑问,ebp-88h这个地址就是变量n的地址,如果有所怀疑,可以比较一下n的地址和ebp-88h的值即可确信这一点。而0x20个双字就是128个字节,正是big_thing的大小。现在可以将这段汇编略微还原了:
return_test(ebp-1D0h)
memcpy(&n, (void*)eax, sizeof(n));
可见,return_test返回的结构体仍然是由eax传出的,只不过这次eax存储的是结构体的指针。那么return_test具体是如何返回一个结构体的呢?看看return_test的实现:
big_thing return_test()
{
...
big_thing b;
b.buf[0] = 0;
004113C8 mov byte ptr [ebp-88h],0
return b;
004113CF mov ecx,20h
004113D4 lea esi,[ebp-88h]
004113DA mov edi,dword ptr [ebp+8]
004113DD rep movs dword ptr es:[edi],dword ptr [esi]
004113DF mov eax,dword ptr [ebp+8]
}
在这里,ebp-88h存储的是return_test的局部变量b。根据rep movs的功能,004113CF处4条指令可以翻译成如下的代码:
memcpy([ebp+8],&b, 128);
在这里,[ebp+8]指的是*(void**)(ebp+8),即将地址ebp+8上存储的值作为地址,由于ebp实际指向栈上保存的旧的ebp,因此ebp+4指向压入栈中的返回地址,ebp+8则指向函数的参数。而我们知道,return_test是没有真正的参数的,只有一个“伪参数”由函数的调用方悄悄地传入,那就是ebp-1D0h(这里的ebp是return_test调用前的ebp)这个值。换句话说,[ebp+8]=old_ebp-1D0h。
那么main中的ebp-1D0h是什么内容呢?看看main函数一开始初始化的汇编代码:
int main()
{
00411470 push ebp
00411471 mov ebp, esp
00411473 sub esp,1D4h
00411479 push ebx
0041147A push esi
0041147B push edi
0041147C lea edi,[ebp-1D4h]
00411482 mov ecx,75h
00411487 mov eax,0CCCCCCCCh
0041148C rep stos dword ptr es:[edi]
0041148E mov eax,dword ptr [___security_cookie (417000h)]
00411493 xor eax,ebp
00411495 mov dword ptr [ebp-4],eax
main函数在保存了ebp之后,就直接将栈增大了1D4h个字节,因此ebp-1D0h就正好落在这个扩大区域的末尾,而区间[ebp-1D0h, ebp-1D0h + 128)也正好处于这个扩大区域的内部。至于这块区域剩下的内容,则留作它用。下面我们就可以把思路理清了:
- 首先main函数在栈上额外开辟了一片空间,并将这块空间的一部分作为传递返回值的临时对象,这里称为temp。
- 将temp对象的地址作为隐藏参数传递给return_test函数。
- return_test函数将数据拷贝给temp对象,并将temp对象的地址用eax传出。
- return_test返回之后,main函数将eax指向的temp对象的内容拷贝给n。
整个流程如图所示(图中地址和变量位置不正确,随便参考下):
 也可以用伪代码表示如下:
也可以用伪代码表示如下:
void return_test(void *temp)
{
big_thing b;
b.buf[0] = 0;
memcpy(temp, &b, sizeof(big_thing));
eax = temp;
}
int main()
{
big_thing temp;
big_thing n;
return_test(&temp);
memcpy(&n, eax, sizeof(big_thing));
}
毋庸置疑,如果返回值类型的尺寸太大,C语言在函数返回时会使用一个临时的栈上内存区域作为中转,结果返回值对象会被拷贝两次。因而不到万不得已,不要轻易返回大尺寸的对象。为了不失一般性,再看看在Linux下使用gcc 4.03编译出来的代码返回大尺寸对象的情况。下面是其main函数的部分反汇编:
80483bd: 8d 85 f8 fe ff ff lea eax , [ebp-107h]
80483c3: 89 04 24 mov [esp], eax
80483c6: e8 95 ff ff ff call 8048360 <return_test>
80483cb: 83 ec 04 sub esp, 4
80483ce: 8d 8d 78 ff ff ff lea ecx, [ebp-87h]
80483d4: 8d 95 f8 fe ff ff lea edx , [ebp -107h]
80483da: b8 80 00 00 00 mov eax ,80h
80483df: 89 44 24 08 mov [esp+8h], eax
80483e3: 89 54 24 04 mov [esp+4h], edx
80483e7: 89 0c 24 mov [esp], ecx
80483ea: e8 c1 fe ff ff call 80482b0 <memcpy@plt>
与MSVC9的反汇编对比,可以发现,ebp-0x107的位置上是临时对象temp的地址,而ebp-0x87则是n的地址。这样,这段代码和用MSVC9反汇编得到的代码是一样的,都是通过栈上的隐藏参数传递临时对象的地址,只不过在将临时对象写回到实际的目标对象n的时候,MSVC9使用了rep movs指令,而gcc调用了memcpy函数。可见在这里VC和gcc的思路大同小异。最后来看看如果函数返回一个C++对象会如何:
#include <iostream>
using namespace std;
struct cpp_obj
{
cpp_obj()
{
cout << "ctor\n";
}
cpp_obj(const cpp_obj& c)
{
cout << "copy ctor\n";
}
cpp_obj& operator=(const cpp_obj& rhs)
{
cout << "operator=\n";
return *this;
}
~cpp_obj()
{
cout << "dtor\n";
}
};
cpp_obj return_test()
{
cpp_obj b;
cout << "before return\n";
return b;
}
int main()
{
cpp_obj n;
n = return_test();
}
在没有开启任何优化的情况下,直接运行一下,可以发现程序输出为:
ctor
ctor
before return
copy ctor
dtor
operator=
dtor
dtor
函数返回之后,进行了一个拷贝构造函数的调用,以及一次operator=的调用,也就是说,仍然产生了两次拷贝。因此C++的对象同样会产生临时对象。 返回对象的拷贝情况完全不具备可移植性,不同的编译器产生的结果可能不同。反汇编main函数来确认这一点:
n = return_test();
00411C2C lea eax,[ebp-0DDh]
00411C32 push eax
00411C33 call return_test (4111F4h)
00411C38 add esp,4
00411C3B mov dword ptr [ebp-0E8h],eax
00411C41 mov ecx,dword ptr [ebp-0E8h]
00411C47 mov dword ptr [ebp-0ECh],ecx
00411C4D mov byte ptr [ebp-4],1
00411C51 mov edx,dword ptr [ebp-0ECh]
00411C57 push edx
00411C58 lea ecx,[ebp-11h]
00411C5B call cpp_obj::operator= (41125Dh)
00411C60 mov byte ptr [ebp-4],0
00411C64 lea ecx,[ebp-0DDh]
00411C6A call cpp_obj::~cpp_obj (41119Ah)
可以看出,这段汇编与之前的版本结构是一致的,临时对象的地址仍然通过隐藏参数传递给函数,只不过最后没有使用rep movs来拷贝数据,而是调用了函数的operator=来进行。同时,这里还对临时对象调用了一次析构函数。 函数传递大尺寸的返回值所使用的方法并不是可移植的,不同的编译器、不同的平台、不同的调用惯例甚至不同的编译参数都有权力采用不同的实现方法。因此尽管我们实验得到的结论在MSVC和gcc下惊人地相似,也不要认为大对象传递只有这一种情况。
由于C++返回对象有两次拷贝的开销,因此C++程序中都尽量避免返回对象。此外,为了减小返回对象的开销,C++提出了返回值优化(Return Value Optimization, RVO)技术,可以将某些场合下的对象拷贝减少1次,如:
cpp_obj return_test()
{
return cpp_obj();
}
返回值优化的做法是直接将对象构造在传出时使用的临时对象上,因此少一次复制。
堆与内存管理
由于在任意时刻,程序都可能发出申请或释放内存的请求,内存大小从几个字节到数GB,导致堆管理较为复杂。
什么是堆
堆是一块巨大的内存空间,常常占据整个虚拟空间的绝大部分。在这片空间里,程序可以请求一块连续内存,并自由地使用,这块内存在程序主动放弃之前都会一直保持有效。
如果让内核提供系统调用来申请和释放内存,由于系统调用的开销很大,频繁的申请和释放,会导致性能较差。事实上管理堆空间分配的往往是程序的运行库,
运行库向操作系统“批发”一块较大的堆空间,然后“零售”给程序。当全部“售完”或程序有大量的内存需求时,再根据实际需求向操作系统“进货”。运行库必须管理它批发来的堆空间,不能把同一块地址出售两次,导致地址的冲突。运行库使用堆的分配算法来管理堆空间。先看看运行库是怎么向操作系统批发内存的。
Linux进程堆管理
进程的地址空间中,除了可执行文件、共享库和栈之外,剩余的未分配的空间都可以被用来作为堆空间。Linux的进程堆管理提供了两种堆空间分配的方式,即两个系统调用:brk()和mmap()。brk()的声明如下:
int brk(void* end_data_segment)
brk()的作用实际上就是设置进程数据段的结束地址,即它可以扩大或者缩小数据段(Linux下数据段和BSS合并在一起统称数据段)。如果将数据段的结束地址向高地址移动,那么扩大的那部分空间作为堆空间是最常见的做法之一。Glibc中还有一个函数叫sbrk,它的功能与brk类似,只不过参数和返回值略有不同。sbrk以一个增量(Increment)作为参数,即需要增加(负数为减少)的空间大小,返回值是增加(或减少)后数据段结束地址,这个函数实际上是对brk系统调用的包装,它是通过brk()实现的。
mmap()的作用和Windows系统下的VirtualAlloc很相似,它的作用就是向操作系统申请一段虚拟地址空间,这块空间可以映射到某个文件(这也是这个系统调用的最初的作用),当它不将地址空间映射到某个文件时,称这块空间为匿名(Anonymous)空间,匿名空间就可以拿来作为堆空间。它的声明如下:
void *mmap(
void *start,
size_t length,
int prot,
int flags,
int fd,
off_t offset);
mmap的前两个参数分别用于指定需要申请的空间的起始地址和长度,如果起始地址设置为0,那么Linux系统会自动挑选合适的起始地址。prot/flags这两个参数用于设置申请的空间的权限(可读、可写、可执行)以及映射类型(文件映射、匿名空间等),最后两个参数是用于文件映射时指定文件描述符和文件偏移的,这里忽略它们。
glibc的malloc函数是这样处理用户的空间请求的:对于小于128KB的请求来说,它会在现有的堆空间里面,按照堆分配算法为它分配一块空间并返回;对于大于128KB的请求来说,它会使用mmap()函数为它分配一块匿名空间,然后在这个匿名空间中为用户分配空间。直接使用mmap也可以轻而易举地实现malloc函数:
void *malloc(size_t nbytes)
{
void* ret = mmap(0, nbytes, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, 0, 0);
if (ret == MAP_FAILED)
return 0;
return ret;
}
mmap()申请的空间的起始地址和大小都必须是系统页的大小的整数倍,对于字节数很小的请求如果也使用mmap的话,无疑是会浪费大量的空间的,所以上述的做法仅仅是演示而已,不具有实用性。
再来分析一下malloc到底一次能够申请的最大空间是多少?从下图可知在有共享库的情况下,留给堆可以用的空间还有两处。第一处是从BSS段结束到0x40000000,即大约1GB不到的空间;第二处是从共享库到栈的这块空间,大约是2GB不到。这两块空间大小都取决于栈、共享库的大小和数量。于是可以估算到malloc最大的申请空间大约是2 GB不到,这似乎与在前面得到的2.9GB的实验结论并不一致。
那么事实是怎么样的呢?实际上2.9GB的结论是对的,2GB的推论也并没有错。造成这种差异的是因为不同的Linux内核版本造成的。因为在布局图里面所看到的共享库的装载地址为0x40000000,这实际上已经是过时了的,在Linux内核2.6版本里面,共享库的装载地址已经被挪到了靠近栈的位置,即位于0xbfxxxxxx附近,所以从0xbfxxxxxx到进程用brk()设置的边界末尾简直是一马平川,中间没有任何空间占用的情况(如果使用静态链接来产生可执行文件,这样就更没有共享库的干扰了)。所以从理论可以推论,2.6版的Linux的malloc的最大空间申请数应该在2.9GB左右(其中可执行文件占去一部分、0x080400000之前的地址占去一部分、栈占去一部分、共享库占去一部分)。
还有其他诸多因素会影响malloc的最大空间大小,比如系统的资源限制(ulimit)、物理内存和交换空间的总和等。原书作者:曾经在一台只有512MB内存和1.5GB交换空间的机器上测试malloc的最大空间申请数,无论怎样结果都不会超过1.9GB左右,让我十分困惑。后来发现原来是内存+交换空间的大小太小,导致mmap申请空间失败。因为mmap申请匿名空间时,系统会为它在内存或交换空间中预留地址,但是申请的空间大小不能超出空闲内存+空闲交换空间的总和。
Windows进程堆管理
windwos进程的地址空间分布:
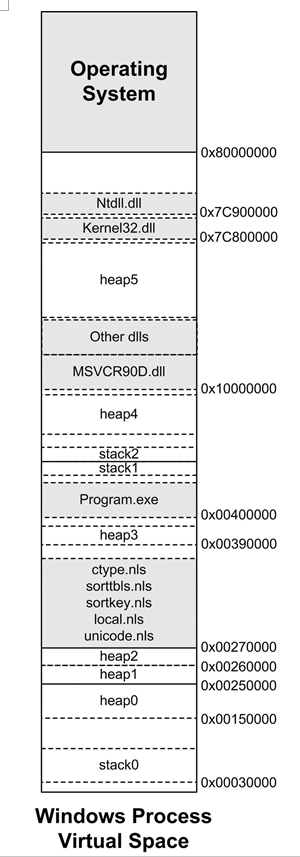
可以看到,Windows的进程将地址空间分配给了各种EXE、DLL文件、堆、栈。其中EXE文件一般位于0x00400000起始的地址;而一部分DLL位于0x10000000起始的地址,如运行库DLL;还有一部分DLL位于接近0x80000000的位置,如系统DLL,NTDLL.DLL、Kernel32.DLL。
栈的位置则在0x00030000和EXE文件后面都有分布,为什么Windows需要这么多栈呢?每个线程的栈都是独立的,所以一个进程中有多少个线程,就应该有多少个对应的栈,对于Windows来说,每个线程默认的栈大小是1MB,在线程启动时,系统会为它在进程地址空间中分配相应的空间作为栈,线程栈的大小可以由创建线程时CreateThread的参数指定。
在分配完上面这些地址以后,Windows的进程地址空间已经是支离破碎了。当程序向系统申请堆空间时,只好从这些剩下的还没有被占用的地址上分配。Windows系统提供了一个API叫做VirtualAlloc(),用来向系统申请空间,它与Linux下的mmap非常相似。实际上VirtualAlloc()申请的空间不一定只用于堆,它仅仅是向系统预留了一块虚拟地址,应用程序可以按照需要随意使用。在使用VirtualAlloc()函数申请空间时,系统要求空间大小必须为页的整数倍。
Windows堆管理器(Heap Manager)提供了一套与堆相关的API用来创建、分配、释放和销毁堆空间:
- HeapCreate:创建一个堆。
- HeapAlloc:在一个堆里分配内存。
- HeapFree:释放已经分配的内存。
- HeapDestroy:摧毁一个堆。
这四个API的作用很明显,HeapCreate就是创建一个堆空间,它会向操作系统批发一块内存空间(它也是通过VirtualAlloc()实现的),而HeapAlloc就是在堆空间里面分配一块小的空间并返回给用户,如果堆空间不足的话,它还会通过VirtualAlloc向操作系统批发更多的内存直到操作系统也没有空间可以分配为止。HeapFree和HeapDestroy的作用就更不言而喻了。
Windows堆管理器存在于两个位置。一份是位于NTDLL.DLL中,它是Windows操作系统用户层的最底层DLL,负责Windows子系统DLL与Windows内核之间的接口,所有用户程序、运行时库和子系统的堆分配都是使用这部分的代码;另一份在Windows内核Ntoskrnl.exe中,负责Windows内核中的堆空间分配(内核堆和用户的堆不是同一个),Windows内核、内核组件、驱动程序使用堆时用到的都是这份堆分配代码,内核堆管理器的接口都由RtlHeap开头。
每个进程在创建时都会有一个默认堆,这个堆在进程启动时创建,并且直到进程结束都一直存在。默认堆的大小为1MB,可以通过链接器的/HEAP参数指定默认堆大小。如果使用超过,堆管理器就会扩展堆的大小,它会通过VirtualAlloc向系统申请更多的空间。
由上图可知一个进程中能够分配给堆用的空间不是连续的。所以当一个堆的空间已经无法再扩展时,就必须创建一个新的堆。但是这一切都不需要用户操作,因为运行库的malloc函数已经解决了这一切,它实际上是对Heapxxxx系列函数的包装,当一个堆空间不够时,它会在进程中创建额外的堆。
所以进程中可能存在多个堆,但是一个进程中一次性能够分配的最大的堆空间取决于最大的那个堆。上图中,Heap5应该是最大的一个堆,它的大小大约是1.5GB~1.7GB,这取决于进程所加载的DLL数量和大小。
堆分配算法
堆空间是程序向操作系统申请的一大块地址空间,堆分配算法用于管理堆,按照需求分配、释放其中的空间。
空闲链表
空闲链表(Free List):利用空闲空间开头的头(header)结构,将所有空闲块连接起来形成一个链表,当用户请求一块空间时,遍历整个列表,直到找到合适大小的块并且将它拆分;当用户释放空间时将它合并到空闲链表中。如下图所示:
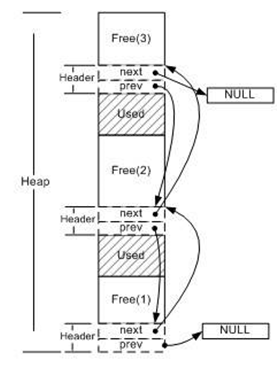 这样的空闲链表实现尽管简单,但在释放空间的时候,给定一个已分配块的指针,堆无法确定这个块的大小。一个简单的解决方法是多分配4字节用于保存大小。
这是最简单的一种分配策略,还存在很多问题。例如,一旦链表被破坏,或者记录长度的那4字节被破坏,整个堆就无法正常工作,而这些数据恰恰很容易被越界读写所接触到。
这样的空闲链表实现尽管简单,但在释放空间的时候,给定一个已分配块的指针,堆无法确定这个块的大小。一个简单的解决方法是多分配4字节用于保存大小。
这是最简单的一种分配策略,还存在很多问题。例如,一旦链表被破坏,或者记录长度的那4字节被破坏,整个堆就无法正常工作,而这些数据恰恰很容易被越界读写所接触到。
位图
位图(Bitmap)的核心思想是将整个堆划分为大量相同大小的块(block),当用户请求内存的时候,总是分配整数个块的空间给用户,
第一块称为已分配区域的头(Head),其余的称为已分配区域的主体(Body)。使用一个整数数组来记录块的使用情况,
由于每个块只有“头/主体/空闲”三种状态,因此仅仅需要两位即可表示一个块。如下图所示:
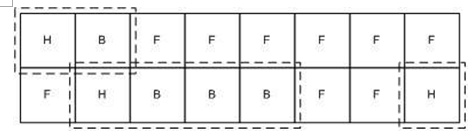 这个堆分配了3片内存,分别有2/4/1个块,用虚线框标出。其对应的位图将是:
这个堆分配了3片内存,分别有2/4/1个块,用虚线框标出。其对应的位图将是:
(HIGH) 11 00 00 10 10 10 11 00 00 00 00 00 00 00 10 11 (LOW)
其中11表示H(Head),10表示主体(Body),00表示空闲(Free)。
优点:
- 速度快:由于整个堆的空闲信息存储在一个数组内,因此访问该数组时cache容易命中。
- 稳定性好:为了避免用户越界读写破坏数据,只须简单地备份一下位图即可。而且即使部分数据被破坏,也不会导致整个堆无法工作。
- 块不需要额外信息,易于管理。
缺点:
- 分配内存的时候容易产生碎片。
- 若堆很大,或者设定的一个块很小,那么位图将会很大,失去cache命中率高的优势,而且也会浪费一定的空间。这种情况可以使用多级位图。
对象池
对象池适用于分配对象的大小是较为固定的几个值的场合。
对象池的思路是,假设每次分配的大小相同,把堆对空间划分为大量请求大小的块,每次分配一个块。
对象池的管理方法可以采用空闲链表,也可以采用位图,与它们的区别仅仅在于它假定了每次请求的都是一个固定的大小,因此实现起来很容易。由于每次总是只请求一个单位的内存,因此请求得到满足的速度非常快,无须查找一个足够大的空间。
实际应用中,堆的分配算法往往是采取多种算法复合而成。比如对于glibc来说,它对于小于64字节的空间申请是采用类似于对象池的方法;而对于大于512字节的空间申请采用的是最佳适配算法;对于大于64字节而小于512字节的,它会根据情况采取上述方法中的最佳折中策略;对于大于128KB的申请,它会使用mmap机制直接向操作系统申请空间。