共享内存与同步
CUDA C支持共享内存,将CUDA C关键字__shared__添加到变量声明中,将使这个变量驻留在共享内存中。对在GPU上启动的每个线程块,CUDA C编译器都将创建该变量的一个副本。线程块中的每个线程都共享这块内存,但线程无法看到也不能修改其他线程块的变量副本。共享内存缓冲区驻留在物理GPU上,而不是GPU之外的系统内存中。因此访问共享内存时的延迟远远低于访问普通缓冲区的延迟,使得共享内存像每个线程块的高速缓存或者中间结果暂存器那样高效。
const int N = 33*1024;
const int threadsPerBlock = 256;
__global__ void dot(float *a, float *b, float *c)
{
__shared__ float cache[threadsPerBlock];
int tid = threadIdx.x + blockId.x*blockDim.x;
int cacheIndex = threadIdx.x;
float temp = 0;
while(tid<N){
temp += a[tid]*b[tid];
tid += blockDim.x * gridDim.x;
}
cache[cacheIndex] = temp;
__syncthreads();
int i = blockDim.x/2;
while(i != 0){
if(cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
i /= 2;
}
if(cacheIndex == 0)
c[blockIdex.x] = cache[0];
}
__syncthreads()函数调用将确保线程块中的每个线程都执行完__syncthreads()前面的语句后,才会执行下一条语句。
常量内存与事件
常量内存:
常量内存用于保存在核函数执行期间不会发生变化的数据,在变量面前添加 __constant__修饰符:
__constant__ Sphere s[SPHERES];
cudaMemcpyToSymbol(s, temp_s, sizeof(Sphere)*SPHERES);
这个特殊版本的cudaMemcpy()用于将主机内存复制到GPU上的常量内存。
从常量内存读取相同的数据可以节约内存带宽,主要原因:
- 对常量内存的单次读操作可以广播到其他的“邻近”线程,这将节约15次读取操作
- 常量内存的数据将缓存起来,因此对相同地址的连续读操作将不会产生而额外的内存通信量。
解释:
- 如果在半线程束中的每个线程都从常量内存的相同地址上读取数据,那么GPU只会产生一个读取请求并在随后将数据广播到每个线程。如果从常量内存中读取大量的数据,那么这种方式产生的内存流量只是使用全局内存的1/16.
- 另外由于这块内存的内容是不会发生变化的, 因此硬件将主动把这个常量数据缓存在GPU上。在第一次从常量内存的某个地址上读取后,当其他的半线程束请求同一个地址时,将命中缓存,这同样减少了额外的内存流量。
- 然而,使用常量内存也可能对性能产生负面影响。如果半线程束中的所有16个线程需要访问常量内存中不同的数据,那么这个16次不同的读取操作会被串行化,从而需要16倍的时间发出请求。但如果从全局内存中读取,那么这些请求会同时发出。这种情况下,从常量内存读取就慢于从全局内存中读取。
事件:
CUDA的事件本质上是一个GPU时间戳,这个时间戳是在用户指定的时间点上记录的。应该将cudaEventRecord()视为一条记录当前时间的语句, 并且把这条语句放入GPU的未完成队列中。因此直到GPU执行完了在调用cudaEventRecord()之前的所有语句时,事件才会被记录下来。为了安全的读取stop值,需要告诉CPU在某个事件上同步,这个函数就是cudaEventSynchronize().当该函数返回时,代表stop事件之前的所有GPU工作已完成,stop可以安全读取。
由于CUDA事件是直接在GPU上实现的,因此不适用于同时包含设备代码和主机代码的混合代码计时,也就是说如果试图通过CUDA事件对核函数和设备内存复制之外的代码进行计时,将得到不可靠的结果。
cudaEvent_t start,stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
//在GPU上执行一些工作
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float elapseTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
纹理内存
纹理内存:
与常量内存类似,纹理内存是另一种形式的只读内存,并且同样缓存在芯片上。因此某些情况下能够减少对内存的请求并提供高效的内存带宽。纹理内存是专门为那些在内存访问模式中存在大量空间局部性的图形应用程序设计的。
首先,需要将输入的数据声明为texture类型的引用:
texture<float> texIn;
在为缓冲区分配了GPU内存后,需要通过cudaBindTexture()将这些变量绑定到内存缓冲区。这相当于告诉CUDA:
- 我们希望将指定的缓冲区作为纹理来使用。
- 我们希望将纹理引用作为纹理的“名字”
cudaMalloc((void**)&data.dev_inSrc, imageSize);
cudaBindTexture(NULL, texIn, data.dev_inSrc, imageSize);
当读取核函数中的纹理时,需要通过特殊的函数来告诉GPU将读取请求转发到纹理内存而不是标准的全局内存。因此,当读取内存时不再使用方括号从缓冲区中读取,而是改为使用tex1Dfetch()。
纹理引用必须声明为文件作用域内的全局变量。tex1Dfetch是一个编译器内置函数,编译器需要在编译的时候知道tex1Dfetch()应该对哪些纹理采样。
tex1Dfetch(texIn, offset);
清除纹理绑定:
cudaUnbindTexTure(texIn);
二维纹理内存:
//声明
texture<float,2> texConstSrc;
//读取
tex2D(texConstSrc, x, y);
//绑定
cudaChannelFormatDesc desc = cudaCreateChannelDesc<float>();
//纹理的维数(DIM*DIM),通道描述符desc
cudaBindTexture2D(NULL, textConstSrc, data.dev_constSrc, desc, DIM, DIM, sizeof(float)*DIM)
//解绑
cudaUnbindTexture(texConstSrc);
一维纹理和二维纹理在性能上没有差异。
原子操作
1.1以上计算功能集支持全局内存上的原子操作, 1.2以上支持共享内存上的原子操作。 atomicAdd(add,y)将生成一个原子的操作序列,这个操作序列包括读取地址addr处的值,将y增加到这个值,以及将结果保存回地址addr。 一个统计字符出现频率的直方图GPU内核函数:
__global__ void histo_kernel(unsigned char* buffer, long size, unsigned int* histo){
__shared__ unsigned int temp[256];
tmp[threadIdx.x] = 0;
__syncThreads();
int i = threadIdx.x + blockIdx.x * blockDim.x;
int offset = blockDim.x * gridDim.x;
while(i<size){
atomicAdd( &temp[buffer[i]], 1);
i += offset;
}
__syncthreads();
atomicAdd( &(histo[threadIdx.x]), temp[threadIdx.x]);
}
通过降低内存竞争程度的策略来提高性能
流
页锁定主机内存
c库函数malloc()分配标准的,可分页(Pagable)的内存,cudaHostAlloc()分配页锁定的主机内存。页锁定内存也称为固定内存(Pinned Memory)或者不可分页内存,它有个重要属性:操作系统将不会对这块内存分页并交换到磁盘上,从而确保了该内存始终驻留在物理内存中。因此,操作系统能够安全的使某个应用程序访问该内存的物理地址,因为这块内存将不会被破坏或者重新定位。
由于GPU知道内存的物理地址,因此可以通过“直接内存访问(Direct Memory Access ,DMA)”技术来在GPU和主机之间复制数据。由于DMA在执行复制时无需CPU的介入,这也就同样意味着,CPU可能在DMA的执行过程中将目标内存交换到磁盘上,或者通过更新操作系统的可分页表来重新定位目标内存的物理地址。CPU可能会移动可分页的数据,这就可能对DMA操作造成延迟。因此,在DMA复制过程中使用固定内存是非常重要的。事实上,当使用可分页内存进行复制时,CUDA驱动程序仍然会通过DMA把数据传输给GPU。因此,复制操作将执行两遍,第一遍从可分页内存复制到一块临时的页锁定内存,然后再从这个页锁定内存复制到GPU上。因此,每当从可分页内存中执行复制操作时,复制速度将受限于PCIE传输速度和系统前端总线速度相对较低的一方。
当使用固定内存时,将失去虚拟内存的所有功能,导致系统更快的耗尽内存,降低系统整体性能。建议,仅对cudaMemcpy()调用中的源内存或者目标内存,才使用锁定内存,并且不再需要使用它们时立即释放,而不是等到应用程序关闭时才释放。
CUDA 流
CUDA流表示一个GPU操作队列,并且该队列中的操作将以指定的顺序执行。可以将每个流视为GPU的一个任务,并且这些任务可以并行执行。 选择一个支持设备重叠功能的设备:
cudaDeviceProp prop;
int whichDevice;
cudaGetDevice(&whichDevice);
cudaGetDevice(&prop, whichDevice);
if(!prop.deviceOverlap){
printf("Device will not handle overlaps , so no speed up from streams\n");
}
创建流:
cudaStream_t stream;
cudaStreamCreate(&stream);
使用流:
for(int i =0; i< FULL_DATA_SIZE; i+=N){
cudaMemcpyAsync(dev_a, host_a + i, N*sizeof(int),cudaMemcpyHostToDevice, stream);
cudamemcpyAsync(dev_b, host_b + i, N*sizeof(int),cudaMemcpyHostToDevice, stream);
kernel<<<N/256,256,0,stream>>>(dev_a, dev_b,dev_c);
cudaMemcpyAsync(host_c + i, dev_c, N*sizeof(int),cudaMemcpyDeviceToHost, stream);
}
任何传递给cudaMemcpyAsync的主机内存指针都必须已经通过cudaHostAlloc分配好内存,也就是说,你只能以异步方式对页锁定内存进行复制操作。
GPU与主机同步,调用cudaStreamSynchronize()并制定想要等待的流:
cudaStreamSynchronize(stream);
释放流:
cudaStreamDestroy(stream)
使用多个流
for(int i =0; i< FULL_DATA_SIZE; i+= 2*N){
cudaMemcpyAsync(dev_a0, host_a + i, N*sizeof(int),cudaMemcpyHostToDevice, stream0);
cudamemcpyAsync(dev_b0, host_b + i, N*sizeof(int),cudaMemcpyHostToDevice, stream0);
kernel<<<N/256,256,0,stream0>>>(dev_a0, dev_b0,dev_c0);
cudaMemcpyAsync(host_c + i, dev_c0, N*sizeof(int),cudaMemcpyDeviceToHost, stream0);
//第二个流
cudaMemcpyAsync(dev_a1, host_a + i + N, N*sizeof(int),cudaMemcpyHostToDevice, stream1);
cudamemcpyAsync(dev_b1, host_b + i + N, N*sizeof(int),cudaMemcpyHostToDevice, stream1);
kernel<<<N/256,256,0,stream1>>>(dev_a1, dev_b1,dev_c1);
cudaMemcpyAsync(host_c + i + N, dev_c1, N*sizeof(int),cudaMemcpyDeviceToHost, stream1);
}
cudaStreamSynchronize(stream0);
cudaStreamSynchronize(stream1);
GPU的工作调度机制
在硬件中并没有流的概念,而是包含一个或多个引擎(主机到设备,设备到主机可能是分开的两个引擎)来执行内存复制操作,以及一个引擎来执行核函数。这些引擎彼此独立的对操作进行排队,因此导致下图所示任务调度情形
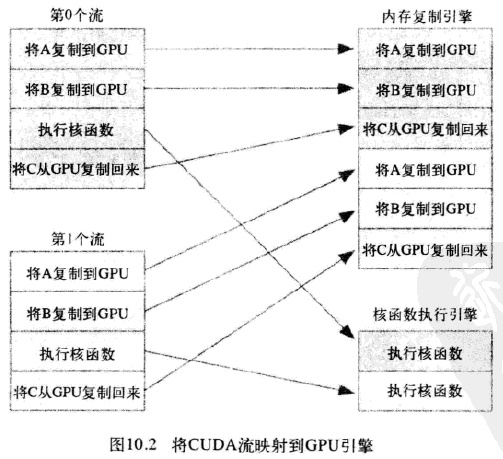
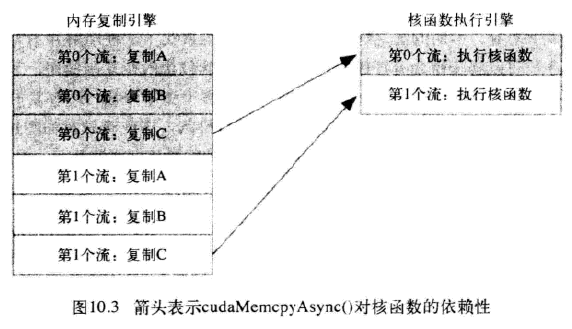
应用程序首先将第0个流的所有操作放入队列,然后是第一个流的所有操作。CUDA驱动程序负责按照这些操作的顺序把他们调度到硬件上执行,这就维持了流内部的依赖性。图10.3说明了这些依赖性,箭头表示复制操作要等核函数执行完成之后才能开始。
于是得到这些操作在硬件上执行的时间线
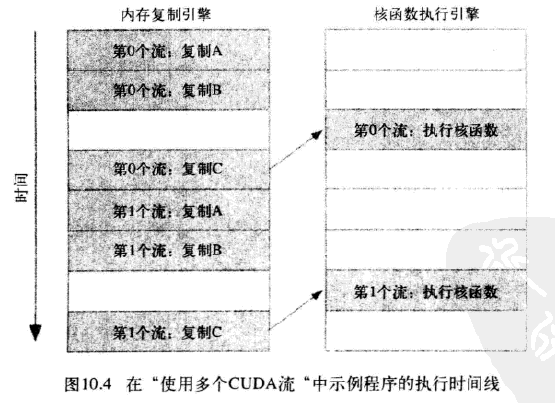
由于第0个流中将c复制回主机的操作要等待核函数执行完成,因此第1个流中将a和b复制到GPU的操作虽然是完全独立的,但却被阻塞了,这是因为GPU引擎是按照指定的顺序来执行工作。记住,硬件在处理内存复制和核函数执行时分别采用了不同的引擎,因此我们需要知道,将操作放入流队列中的顺序将影响着CUDA驱动程序调度这些操作以及执行的方式。
高效使用多个流
如果同时调度某个流的所有操作,那么很容易在无意中阻塞另一个流的复制操作或者核函数执行。要解决这个问题,在将操作放入流的队列时应采用宽度优先方式,而非深度优先方式。如下代码所示:
for(int i =0; i< FULL_DATA_SIZE; i+= 2*N){
cudaMemcpyAsync(dev_a0, host_a + i, N*sizeof(int),cudaMemcpyHostToDevice, stream0);
cudaMemcpyAsync(dev_a1, host_a + i + N, N*sizeof(int),cudaMemcpyHostToDevice, stream1);
cudamemcpyAsync(dev_b0, host_b + i, N*sizeof(int),cudaMemcpyHostToDevice, stream0);
cudamemcpyAsync(dev_b1, host_b + i + N, N*sizeof(int),cudaMemcpyHostToDevice, stream1);
kernel<<<N/256,256,0,stream0>>>(dev_a0, dev_b0,dev_c0);
kernel<<<N/256,256,0,stream1>>>(dev_a1, dev_b1,dev_c1);
cudaMemcpyAsync(host_c + i, dev_c0, N*sizeof(int),cudaMemcpyDeviceToHost, stream0);
cudaMemcpyAsync(host_c + i + N, dev_c1, N*sizeof(int),cudaMemcpyDeviceToHost, stream1);
}
如果内存复制操作的时间与核函数执行的时间大致相当,那么新的执行时间线将如图10.5所示,在新的调度顺序中,依赖性仍然能得到满足:
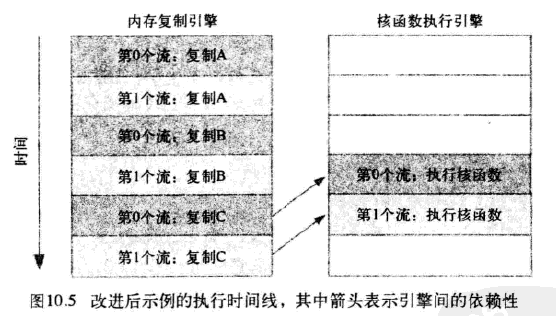
由于采用了宽度优先方式将操作放入各个流的队列中,因此第0个流对c的复制操作将不会阻塞第1个流对a和b的内存复制操作。这使得GPU能够并行的执行复制操作和核函数,从而使应用程序的运行速度显著加快。
零拷贝主机内存
The easy way to achieve copy/compute overlap!
- Enable Host Mapping*
Runtime: cudaSetDeviceFlags() with cudaDeviceMapHost flag
Driver : cuCtxCreate() with CU_CTX_MAP_HOST
- Allocate pinned CPU memory
Runtime: cudaHostAlloc(), use cudaHostAllocMapped flag
Driver : cuMemHostAlloc()use CUDA_MEMHOSTALLOC_DEVICEMAP
- Get a CUDA device pointer to this memory
Runtime: cudaHostGetDevicePointer()
Driver : cuMemHostGetDevicePointer()
- Just use that pointer in your kernels!
Zero-Copy Guidlines
- Data is transferred over the PCIe bus automatically, but it’s slow
- Use when data is only read/written once
- Use for very small amounts of data (new variables, CPU/GPU communication)
- Use when compute/memory ratio is very high and occupancy is high, so latency over PCIe is hidden
- Coalescing is critically important!