二叉搜索树(Binary Search Tree,后文简写 BST)
首先,BST 的特性大家应该都很熟悉了:
1、对于 BST 的每一个节点node,左子树节点的值都比node的值要小,右子树节点的值都比node的值大。
2、对于 BST 的每一个节点node,它的左侧子树和右侧子树都是 BST。
从做算法题的角度来看 BST,除了它的定义,还有一个重要的性质:BST 的中序遍历结果是有序的(升序)
寻找第 K 小的元素
给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 个最小元素(从 1 开始计数)
分析:中序遍历升序,因此直接得出以下代码:
int kthSmallest(TreeNode root, int k) {
// 利用 BST 的中序遍历特性
traverse(root, k);
return res;
}
// 记录结果
int res = 0;
// 记录当前元素的排名
int rank = 0;
void traverse(TreeNode root, int k) {
if (root == null) {
return;
}
traverse(root.left, k);
/* 中序遍历代码位置 */
rank++;
if (k == rank) {
// 找到第 k 小的元素
res = root.val;
return;
}
/*****************/
traverse(root.right, k);
}
上面的算法时间复杂度O(n), 可以通过在二叉树节点中维护额外信息来达到对数级复杂度。
每个节点需要记录,以自己为根的这棵二叉树有多少个节点。
也就是说,我们TreeNode中的字段应该如下:
class TreeNode {
int val;
// 以该节点为根的树的节点总数
int size;
TreeNode left;
TreeNode right;
}
有了size字段,外加 BST 节点左小右大的性质,对于每个节点node就可以通过node.left推导出node的排名,从而做到我们刚才说到的对数级算法。
比如说你让我查找排名为k的元素,当前节点知道自己排名第m,那么我可以比较m和k的大小:
1、如果m == k,显然就是找到了第k个元素,返回当前节点就行了。
2、如果k < m,那说明排名第k的元素在左子树,所以可以去左子树搜索第k个元素。
3、如果k > m,那说明排名第k的元素在右子树,所以可以去右子树搜索第k - m - 1个元素。
这样就可以将时间复杂度降到O(logN)了。
BST 转化累加树(leetcode 538,1038)
给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
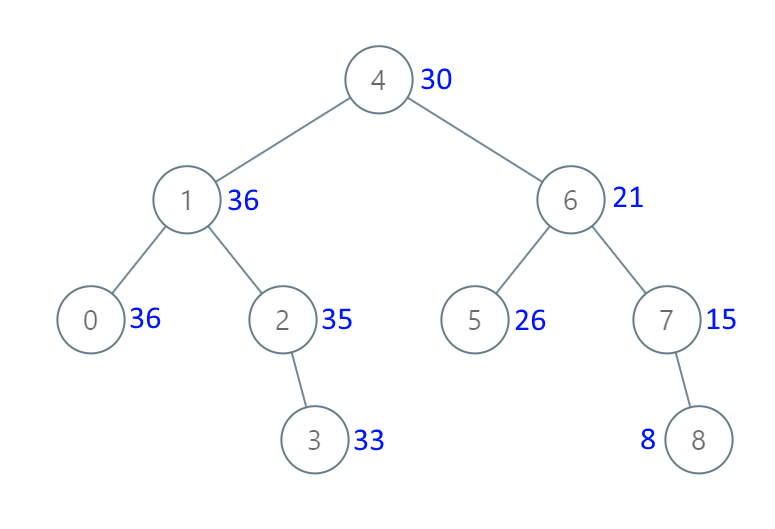
题目应该不难理解,比如图中的节点 5,转化成累加树的话,比 5 大的节点有 6,7,8,加上 5 本身,所以累加树上这个节点的值应该是 5+6+7+8=26。
我们需要把 BST 转化成累加树,函数签名如下:
TreeNode convertBST(TreeNode root)
分析:
按照二叉树的通用思路,需要思考每个节点应该做什么,但是这道题上很难想到什么思路。
BST 的每个节点左小右大,这似乎是一个有用的信息,既然累加和是计算大于等于当前值的所有元素之和,那么每个节点都去计算右子树的和,不就行了吗?
这是不行的。对于一个节点来说,确实右子树都是比它大的元素,但问题是它的父节点也可能是比它大的元素呀?这个没法确定的,我们又没有触达父节点的指针,所以二叉树的通用思路在这里用不了。
其实,正确的解法很简单,还是利用 BST 的中序遍历特性。
刚才我们说了 BST 的中序遍历代码可以升序打印节点的值:
void traverse(TreeNode root) {
if (root == null) return;
traverse(root.left);
// 中序遍历代码位置
print(root.val);
traverse(root.right);
}
那如果我想降序打印节点的值怎么办?
很简单,只要把递归顺序改一下就行了:
void traverse(TreeNode root) {
if (root == null) return;
// 先递归遍历右子树
traverse(root.right);
// 中序遍历代码位置
print(root.val);
// 后递归遍历左子树
traverse(root.left);
}
这段代码可以从大到小降序打印 BST 节点的值,如果维护一个外部累加变量sum,然后把sum赋值给 BST 中的每一个节点,不就将 BST 转化成累加树了吗?
TreeNode convertBST(TreeNode root) {
traverse(root);
return root;
}
// 记录累加和
int sum = 0;
void traverse(TreeNode root) {
if (root == null) {
return;
}
traverse(root.right);
// 维护累加和
sum += root.val;
// 将 BST 转化成累加树
root.val = sum;
traverse(root.left);
}
核心还是 BST 的中序遍历特性.
简单总结下吧,BST 相关的问题,要么利用 BST 左小右大的特性提升算法效率,要么利用中序遍历的特性满足题目的要求,也就这么些事儿吧。
BST 的基础操作:判断 BST 的合法性、增、删、查
判断BST的合法性
有问题的写法:
boolean isValidBST(TreeNode root) {
if (root == null) return true;
if (root.left != null && root.val <= root.left.val)
return false;
if (root.right != null && root.val >= root.right.val)
return false;
return isValidBST(root.left)
&& isValidBST(root.right);
}
出现问题的原因在于,对于每一个节点root,代码只检查了它的左右孩子节点是否符合左小右大的原则;但是根据 BST 的定义,root的整个左子树都要小于root.val,整个右子树都要大于root.val。
正确的代码:
boolean isValidBST(TreeNode root) {
return isValidBST(root, null, null);
}
/* 限定以 root 为根的子树节点必须满足 max.val > root.val > min.val */
boolean isValidBST(TreeNode root, TreeNode min, TreeNode max) {
// base case
if (root == null) return true;
// 若 root.val 不符合 max 和 min 的限制,说明不是合法 BST
if (min != null && root.val <= min.val) return false;
if (max != null && root.val >= max.val) return false;
// 限定左子树的最大值是 root.val,右子树的最小值是 root.val
return isValidBST(root.left, min, root)
&& isValidBST(root.right, root, max);
}
我们通过使用辅助函数,增加函数参数列表,在参数中携带额外信息,将这种约束传递给子树的所有节点,记住这个二叉树算法技巧。
在 BST 中搜索一个数
boolean isInBST(TreeNode root, int target) {
if (root == null) return false;
if (root.val == target)
return true;
if (root.val < target)
return isInBST(root.right, target);
if (root.val > target)
return isInBST(root.left, target);
// root 该做的事做完了,顺带把框架也完成了,妙
}
于是,我们对原始框架进行改造,抽象出一套针对 BST 的遍历框架:
void BST(TreeNode root, int target) {
if (root.val == target)
// 找到目标,做点什么
if (root.val < target)
BST(root.right, target);
if (root.val > target)
BST(root.left, target);
}
这个代码框架其实和二叉树的遍历框架差不多,无非就是利用了 BST 左小右大的特性而已
在 BST 中插入一个数
上一个问题,我们总结了 BST 中的遍历框架,就是「找」的问题。直接套框架,加上「改」的操作即可。一旦涉及「改」,函数就要返回TreeNode类型,并且对递归调用的返回值进行接收。
TreeNode insertIntoBST(TreeNode root, int val) {
// 找到空位置插入新节点
if (root == null) return new TreeNode(val);
// if (root.val == val)
// BST 中一般不会插入已存在元素
if (root.val < val)
root.right = insertIntoBST(root.right, val);
if (root.val > val)
root.left = insertIntoBST(root.left, val);
return root;
}
在 BST 中删除一个数
这个问题稍微复杂,跟插入操作类似,先「找」再「改」,先把框架写出来再说:
TreeNode deleteNode(TreeNode root, int key) {
if (root.val == key) {
// 找到啦,进行删除
} else if (root.val > key) {
// 去左子树找
root.left = deleteNode(root.left, key);
} else if (root.val < key) {
// 去右子树找
root.right = deleteNode(root.right, key);
}
return root;
}
找到目标节点了,比方说是节点A,如何删除这个节点,这是难点。因为删除节点的同时不能破坏 BST 的性质。有三种情况,用图片来说明。
情况 1:A恰好是末端节点,两个子节点都为空,那么它可以当场去世了。
图片来自 LeetCode
if (root.left == null && root.right == null)
return null;
情况 2:A只有一个非空子节点,那么它要让这个孩子接替自己的位置。
图片来自 LeetCode
// 排除了情况 1 之后
if (root.left == null) return root.right;
if (root.right == null) return root.left;
情况 3:A有两个子节点,麻烦了,为了不破坏 BST 的性质,A必须找到左子树中最大的那个节点,或者右子树中最小的那个节点来接替自己。我们以第二种方式讲解。
图片来自 LeetCode
if (root.left != null && root.right != null) {
// 找到右子树的最小节点
TreeNode minNode = getMin(root.right);
// 把 root 改成 minNode
root.val = minNode.val;
// 转而去删除 minNode
root.right = deleteNode(root.right, minNode.val);
}
三种情况分析完毕,填入框架,简化一下代码:
TreeNode deleteNode(TreeNode root, int key) {
if (root == null) return null;
if (root.val == key) {
// 这两个 if 把情况 1 和 2 都正确处理了
if (root.left == null) return root.right;
if (root.right == null) return root.left;
// 处理情况 3
TreeNode minNode = getMin(root.right);
root.val = minNode.val;
root.right = deleteNode(root.right, minNode.val);
} else if (root.val > key) {
root.left = deleteNode(root.left, key);
} else if (root.val < key) {
root.right = deleteNode(root.right, key);
}
return root;
}
TreeNode getMin(TreeNode node) {
// BST 最左边的就是最小的
while (node.left != null) node = node.left;
return node;
}
删除操作就完成了。注意一下,这个删除操作并不完美,因为我们一般不会通过root.val = minNode.val修改节点内部的值来交换节点,而是通过一系列略微复杂的链表操作交换root和minNode两个节点。
因为具体应用中,val域可能会是一个复杂的数据结构,修改起来非常麻烦;而链表操作无非改一改指针,而不会去碰内部数据。
不过这里我们暂时忽略这个细节,旨在突出 BST 基本操作的共性,以及借助框架逐层细化问题的思维方式。
总结
通过这篇文章,我们总结出了如下几个技巧:
1、如果当前节点会对下面的子节点有整体影响,可以通过辅助函数增长参数列表,借助参数传递信息。
2、在二叉树递归框架之上,扩展出一套 BST 代码框架:
void BST(TreeNode root, int target) {
if (root.val == target)
// 找到目标,做点什么
if (root.val < target)
BST(root.right, target);
if (root.val > target)
BST(root.left, target);
}
3、根据代码框架掌握了 BST 的增删查改操作。