概要
提出了一种称为Corosync Cluster Engine的通用集群基础结构。 提供了这项工作的理由以及项目的历史。 详细描述了该体系结构。 内部编程API旨在为开发人员提供对架构映射的编程模型的基本了解。 最后,提供了使用Corosync Cluster Engine的开源项目示例
介绍
Corosync Cluster Engine[Corosync]团队设计并实现了Corosync Cluster Engine,以满足集群社区的后勤需求。集群开发人员社区的一些成员强烈希望减少技术和社区碎片。 技术碎片导致互操作性方面的困难。不同的项目集群系统不能很好地互操作,因为它们各自以不一致的方式做出关于集群状态的决策。每个集群软件可能采用不同的方法来管理故障,通信,读取配置文件,确定集群成员资格或从故障中恢复。 社区分散导致开发人员分散在许多不同的项目中。大多数项目都有一小部分开发人员。过去,这些开发人员没有使用相同的基础架构,而是实现具有类似功能的代码。然后,该软件部署在各种集群系统中,必须由各个项目进行维护和开发。 Corosync群集引擎通过将核心基础结构与群集服务分离来解决这些问题。通过实现这种抽象,所有集群服务都可以在集群中进行决策。此抽象还统一了一个开源组下的核心代码库,目的是使用OSI批准的许可证维护,开发和引导可重用的集群基础结构。
历史
Corosync Cluster Engine成立于2008年1月,旨在缩小OpenAIS项目。 集群基础结构原语从服务可用性论坛应用程序接口规范API简化为新项目。 这项工作由集群项目的各种维护人员产生,以提高互操作性并统一开发人员。 OpenAIS项目成立于2002年1月,旨在实现服务可用性论坛应用程序接口规范API [SaForumAIS]。 这些API旨在使用群集技术提供高可用性的应用程序框架,以减少MTTR [Dake05]。 在开发OpenAIS期间,基础架构上花费的开发时间比API多。 由于专注于基础架构,因此创建了一个完全可重用的基于插件的集群引擎。
架构
Overview
Corosync Cluster Engine集群由通过互连连接的处理器组成。 本文将互连(interconnect)定义为物理通信系统,它允许多播或广播操作来传递信息包。 本文将处理器(processor)定义为通用计算机,包括CPU,内存,网络接口芯片,物理存储和Linux等操作系统。 这种类型的集群通常称为无共享集群。
Corosync Cluster Engine支持完全组件化的插件架构。 Corosync Cluster Engine的每个组件都可以由在处理器启动时提供相同功能的其他组件替换。
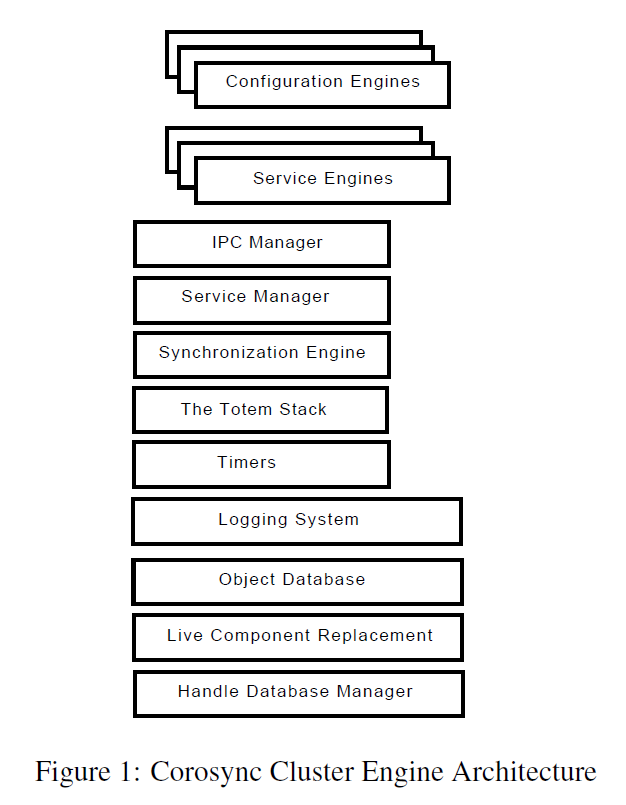 图1描述了Corosync Cluster Engine进程的体系结构。
图1描述了Corosync Cluster Engine进程的体系结构。
本文的小节subsection是根据依赖性而非重要性组织的。 Corosync群集引擎中使用的每个组件对于创建群集软件引擎都至关重要。
Handle Database Manager
句柄数据库管理器提供引用计数数据库,该数据库以O1顺序将唯一的64位句柄标识符映射到内存地址。 然后,库或Corosync Cluster Engine的其他组件可以使用此映射将地址映射到64位值。
句柄数据库支持在数据库中创建和销毁新条目。 最后,存在获取对象数据库条目的引用并释放引用的机制。
垃圾收集自动发生,当句柄的引用计数达到零时,可以调用用户提供的回调来执行句柄信息的销毁。
Live Component Replacement
实时组件更换是Corosync Cluster Engine使用的插件系统。 引擎中的每个组件都是一个动态加载的LCR对象。 LCR对象设计为在运行时可替换,但此功能尚未完全实现。
LCR插件系统与所有其他插件系统的不同之处在于,完整的C接口插入到进程地址空间,而不是简单的一个函数调用。 图2展示了LCR系统的使用。
LCR对象是静态或动态链接的。 引用接口时,将检查内部存储区域以查看对象是否已静态链接。 如果已静态链接,则会向用户提供参考。 如果在内部存储区域中找不到,则将扫描存储介质上的lcrso目录以查找匹配的接口。 如果发现它将被加载并引用给用户; 否则,返回错误
实时组件替换插件系统广泛用于整个Corosync Cluster Engine,以提供接口的动态运行时加载。
struct iface {
void (*func1) (void);
void (*func2) (void);
void (*func3) (void);
};
// Reference version 0 of A and B interfaces
res = lcr_ifact_reference (&a_ifact_handle_ver0,
"A_iface1",
0,/* version 0 */
&a_iface_ver0_p, (void *)0xaaaa0000);
a_iface_ver0 = (struct iface *)a_iface_ver0_p;
res = lcr_ifact_reference (&b_ifact_handle_ver0,
"B_iface1",
0, /* version 0 */
&b_iface_ver0_p,
(void *)0xbbbb0000);
b_iface_ver0 = (struct iface*)b_iface_ver0_p;
a_iface_ver0->func1();
a_iface_ver0->func2();
a_iface_ver0->func3();
lcr_ifact_release(a_ifact_handle_ver0);
b_iface_ver0->func1();
b_iface_ver0->func2();
b_iface_ver0->func3();
lcr_ifact_release(b_ifact_handle_ver0);
Figure 2: Example of using multiple interfaces in one application
Object Database
对象数据库为 配置引擎 和 服务引擎 提供内存中非持久存储机制。
对象数据库是对象的集合。每个对象都有一个名称,并存储在树状结构中。每个对象都有一个父对象。对象内部是对象唯一的key和value对。图3描绘了部分对象数据库布局。
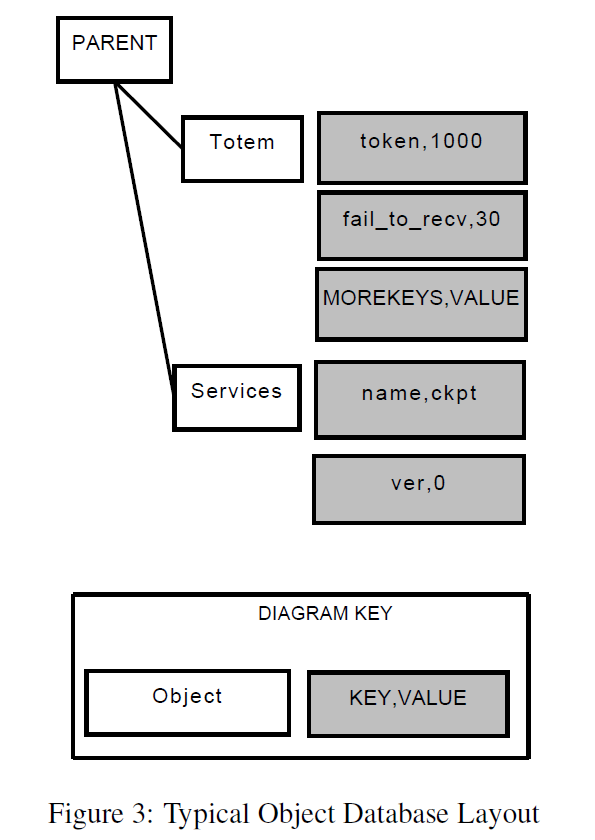 对象数据库提供用于创建,删除和搜索对象的API。该数据库还提供了读取和写入key-value的机制。最后,数据库提供了一种机制来查找对象,迭代树中的对象,以及迭代对象内的key。对象有特定要求。对象数据库允许具有相同名称的多个对象存储在具有相同父对象的数据库中。每个对象可能包含key-value对。对象的key是唯一的,其值是二进制数据块。
由于对象数据库通常用于配置引擎的解析,因此提供了一个特殊的API来自动检测在对象内存储键和关联值时的失败。在对象创建时,可以注册该对象的有效key列表以及每个key的验证回调。如果API的用户在修改对象数据库中的对象时指定了无效的key,则修改请求将被拒绝并出现错误。当key有效时,在修改key之前,将调用验证回调。此验证回调使用用户注册的回调验证value的内容。如果回调返回无效值,则拒绝修改请求。
对象数据库提供用于创建,删除和搜索对象的API。该数据库还提供了读取和写入key-value的机制。最后,数据库提供了一种机制来查找对象,迭代树中的对象,以及迭代对象内的key。对象有特定要求。对象数据库允许具有相同名称的多个对象存储在具有相同父对象的数据库中。每个对象可能包含key-value对。对象的key是唯一的,其值是二进制数据块。
由于对象数据库通常用于配置引擎的解析,因此提供了一个特殊的API来自动检测在对象内存储键和关联值时的失败。在对象创建时,可以注册该对象的有效key列表以及每个key的验证回调。如果API的用户在修改对象数据库中的对象时指定了无效的key,则修改请求将被拒绝并出现错误。当key有效时,在修改key之前,将调用验证回调。此验证回调使用用户注册的回调验证value的内容。如果回调返回无效值,则拒绝修改请求。
Logging System
通用日志记录系统可用于服务引擎以及Corosync Cluster Engine软件栈的其余部分。日志记录系统完全不阻塞,并在进程地址空间中使用单独的线程来过滤和输出日志记录信息。日志记录系统是一般可重用的库,可用于第三方进程以及服务引擎。在多个服务引擎使用日志记录系统的情况下,Corosync Cluster Engine仅创建一个线程。 日志记录系统支持使用完整的printf()样式参数处理进行日志记录。信息可以打印到stderr,文件和/或系统日志。 日志记录系统可以包含任意数量的组件,称为标记,它们允许运行时过滤调试消息和8个级别跟踪消息到日志记录输出介质。每个跟踪类型可以单独过滤,因此特定的跟踪号可以用于特定功能。日志记录系统的一个独特功能是通过定义在文件的C代码开头构造函数初始化日志记录系统和日志记录组件。配置选项也可以在运行时更改。此外,日志记录系统支持fork()系统调用。
Timers
几乎每个服务引擎都需要使用定时器,因此提供了定时器系统。 时间表示自1970年1月1日以来的纳秒。 定时器可以设置为在绝对时间到期。 另一种类型的计时器允许将来在一定数量的纳秒内到期。 当计时器到期时,它执行在计时器创建时注册的回调,以执行服务引擎设计者所需的软件代码
The Totem Stack
The Totem Single Ring Ordering and Membership Protocol实现了完全有序的扩展虚拟同步通信模型。 与许多典型的通信系统不同,扩展的虚拟同步模型要求每个处理器都同意消息的顺序和成员的变化,并且这些消息是完全恢复的。
虚拟同步的属性(称为约定排序)允许集群服务的简单状态同步。 因为每个节点以相同的顺序接收消息,所以一旦Totem协议对消息进行了排序,就会发生消息处理。 这允许群集中的每个节点在发生处理器故障或成员中包含新处理器时保持同步。
Totem栈的一个关键特性是它支持通过多个网络接口进行冗余通信的能力。 使用Totem冗余环协议在多个网络接口上复制包括成员协议的所有数据。
Totem使用用户数据报协议组播完全在用户空间中实现。 协议实现可以配置为在Internet协议版本4网络或Internet协议版本6网络中运行。
在用户配置下,所有通信可以使用安全地存储在所有节点上的私有密钥进行认证和加密。
Configuration Engine
Corosync Cluster Engine通过提供加载特定于应用程序的配置引擎的功能,解决了配置文件独立性问题。 配置引擎提供了一种以特定于应用程序的方式读取和写入配置文件的方法。 这些插件配置Corosync Cluster Engine以及特定于应用程序插件的其他组件。 如果Corosync Cluster Engine执行程序未运行,则应用程序仍可以透明地使用配置引擎来读取和存储配置信息。
Interprocess Communication Manager
进程间通信管理器负责接收和传输IPC请求。 传入的IPC请求通过服务管理器路由到适当的服务引擎插件。 服务引擎可以向第三方进程发送响应。 每个IPC连接都是两个文件描述符的抽象。 一个文件描述符用于第三方进程阻塞请求和响应数据包。 剩余的文件描述符专门用于应由第三方进程执行的非阻塞回调操作。 在Interprocess Communication Manager初始化IPC连接期间,这两个文件描述符相互连接。
Service Engine
服务引擎由第三方创建,以提供某种形式的集群范围服务。 这样的一些示例是服务可用性论坛的应用程序接口规范检查点服务,Pacemaker或CMAN。 服务引擎有一个定义良好的实时组件替换接口,用于运行时链接到服务管理器。 服务引擎负责通过进程间通信管理器通过API或外部控制向用户提供特定类别的集群服务。
Service Manager
服务管理器负责加载和卸载插件服务引擎。 它还负责将所有请求路由到Corosync Cluster Engine中加载的服务引擎。 在Corosync Cluster Engine初始化期间,将加载配置引擎。 然后,配置引擎存储要加载的服务引擎列表。 最后,服务管理器加载每个服务引擎。 服务管理器加载服务后,它负责初始化服务引擎。 当用户通过进程间通信管理器请求操作时,该请求由服务管理器路由到适当的服务引擎。 服务管理器还负责向服务管理器发送成员更改。 服务引擎通过传输消息通过低级别Totem单环协议复制信息。 这些传输的消息通过服务管理器传送到服务引擎。 最后,服务管理器负责与同步引擎路由同步活动。
Synchronization Engine
在失败或添加处理器之后,同步引擎负责指导所有服务引擎的恢复。 服务引擎可以可选地使用同步引擎,或者将同步引擎功能设置为NULL,在这种情况下,它们将不被使用。
同步引擎有四种状态
- sync_init
- sync_process
- sync_activate
- sync_abort
服务引擎同步过程的第一步是初始化。 服务引擎中的sync_init调用存储用于执行由服务引擎设计者创建的恢复算法的信息。
执行sync_process以处理恢复操作。 因为Totem协议传输队列可能在执行恢复的处理器上变满,所以sync_process可能必须返回而不返回负值。 如果同步完成,则应返回零值。
如果在同步期间的任何时间,新处理器加入成员资格或处理器离开成员资格,则将执行sync_abort调用以重置由sync_init创建的任何状态。
在所有节点上完成同步后,将调用sync_activate以激活服务引擎的新数据集。
Default Service Engines
Corosync Cluster Engine提供了一些通用的默认服务引擎。 将来会提供其他默认服务引擎。
Closed Process Group Service Engine
封闭的进程组API和关联的服务引擎负责提供封闭的进程组消息传递语义。 封闭的进程组是进程组语义的特化。
任何进程都可以加入进程组。 进程是具有进程标识符的系统任务,通常称为PID。 加入后,会向成员中的每个进程发送一条加入消息。 加入消息的内容是进程的进程ID和进程正在运行的加入进程的处理器标识符。 当进程自愿离开进程组时,或者由于失败,将向每个剩余的处理器发送离开消息。
封闭的进程组服务引擎允许在已加入进程组的处理器集合之间传输和传递消息。图4中的定义和图5中的API用于实现封闭的进程组系统。在任何时候,此服务都维护扩展的虚拟同步消息传递模型。要加入进程组,cpg_join()用于C程序。用户传递进程组以加入。要保留进程组,请使用cpg_leave()。失败自动表现为进程执行了cpg_leave()函数调用。使用C函数cpg_mcast()将消息发送到进程组中的每个节点。使用cpg_dispatch()C函数调用执行进程成员身份和消息传递的更改。此函数调用cpg_deliver_fn_t()函数来传递消息,并调用cpg_confchg_fn_t()来传递成员资格更改。这些函数在初始化期间使用cpg_initialize()函数调用进行注册。
typedef uint64_t cpg_handle_t;
typedef enum {
CPG_DISPATCH_ONE,
CPG_DISPATCH_ALL,
CPG_DISPATCH_BLOCKING
} cpg_dispatch_t;
typedef enum {
CPG_TYPE_UNORDERED,
CPG_TYPE_FIFO,
CPG_TYPE_AGREED,
CPG_TYPE_SAFE
} cpg_guarantee_t;
typedef enum {
CPG_FLOW_CONTROL_DISABLED,
CPG_FLOW_CONTROL_ENABLED
} cpg_flow_control_state_t;
typedef enum {
CPG_OK = 1,
CPG_ERR_LIBRARY = 2,
CPG_ERR_TIMEOUT = 5,
CPG_ERR_TRY_AGAIN = 6,
CPG_ERR_INVALID_PARAM = 7,
CPG_ERR_NO_MEMORY = 8,
CPG_ERR_BAD_HANDLE = 9,
CPG_ERR_ACCESS = 11,
CPG_ERR_NOT_EXIST = 12,
CPG_ERR_EXIST = 14,
CPG_ERR_NOT_SUPPORTED = 20,
CPG_ERR_SECURITY = 29,
CPG_ERR_TOO_MANY_GROUPS=30
} cpg_error_t;
typedef enum {
CPG_REASON_JOIN = 1,
CPG_REASON_LEAVE = 2,
CPG_REASON_NODEDOWN = 3,
CPG_REASON_NODEUP = 4,
CPG_REASON_PROCDOWN = 5
} cpg_reason_t;
struct cpg_address {
uint32_t nodeid;
uint32_t pid;
uint32_t reason;
};
#define CPG_MAX_NAME_LENGTH 128
struct cpg_name {
uint32_t length;
char value[CPG_MAX_NAME_LENGTH];
};
#define CPG_MEMBERS_MAX 128
Figure 4. The Closed Process Group Interface Definitions
typedef void (*cpg_deliver_fn_t) (
cpg_handle_t handle,
struct cpg_name *group_name,
uint32_t nodeid,
uint32_t pid,
void *msg,
int msg_len);
typedef void (*cpg_confchg_fn_t) (
cpg_handle_t handle,
struct cpg_name *group_name,
struct cpg_address *member_list,
int member_list_entries,
struct cpg_address *left_list,
int left_list_entries,
struct cpg_address *joined_list,
int joined_list_entries);
typedef struct {
cpg_deliver_fn_t cpg_deliver_fn;
cpg_confchg_fn_t cpg_confchg_fn;
} cpg_callbacks_t;
cpg_error_t cpg_initialize (
cpg_handle_t *handle,
cpg_callbacks_t *callbacks);
cpg_error_t cpg_finalize (
cpg_handle_t handle);
cpg_error_t cpg_fd_get (
cpg_handle_t handle, int *fd);
cpg_error_t cpg_context_get (
cpg_handle_t handle, void **context);
cpg_error_t cpg_context_set (
cpg_handle_t handle, void *context);
cpg_error_t cpg_dispatch (
cpg_handle_t handle, cpg_dispatch_t dispatch_types);
cpg_error_t cpg_join (
cpg_handle_t handle,
struct cpg_name *group);
cpg_error_t cpg_leave (
cpg_handle_t handle,
struct cpg_name *group);
cpg_error_t cpg_mcast_joined (
cpg_handle_t handle,
cpg_guarantee_t guarantee,
struct iovec *iovec, int iov_len);
Figure 5: The Closed Process Group Interface API
Configuration Database Service Engine
配置数据库服务引擎向第三方进程提供C编程API,以在对象数据库中读取和写入配置信息。 API与对象数据库中使用的API基本相同。 当Corosync Cluster Engine未运行以进行配置时,配置数据库服务C API可能会运行。 在此操作模式中,在C API的用户对对象数据库进行更改之后,加载配置引擎并自动用于读取或写入对象数据库。
Library Programming Interface
overview
库编程接口对于希望访问Corosync服务引擎的第三方进程非常有用。 库编程接口使用hdb内联库和cslib库提供句柄管理和连接管理
Handle Database API
句柄数据库API(如图6所示)负责管理映射到内存块的句柄。 处理内存块是引用计数,当没有用户引用句柄时,句柄内存区域将自动释放。 API是完全线程安全的,可以在多线程库中使用。
创建句柄数据库时,应使用函数hdb_create()。 在销毁句柄数据库时,应使用函数hdb_destroy()。
要在句柄数据库中创建新条目,请使用函数hdb_handle_create()。 创建句柄后,它将以引用计数1开始。要减少引用计数并释放句柄,应执行函数hdb_handle_destroy()。
使用hdb_handle_create()创建句柄后,可以使用hdb_handle_get()引用它。 此函数将检索与用户指定的句柄相关的内存存储区域。 使用句柄完成库时,应执行hdb_handle_put()。
struct hdb_handle {
int state;
void *instance;
int ref_count;
};
struct hdb_handle_database {
unsigned int handle_count;
struct hdb_handle *handles;
unsigned int iterator;
pthread_mutex_t mutex;
};
void hdb_create (
struct hdb_handle_database
*handle_database);
void hdb_destroy (
struct hdb_handle_database
*handle_database);
int hdb_handle_create (
struct hdb_handle_database *handle_database,
int instance_size,
unsigned int *handle_id_out);
int hdb_handle_get (
struct hdb_handle_database *handle_database,
unsigned long long handle,
void **instance);
void hdb_handle_put (
struct hdb_handle_database *handle_database,
unsigned long long handle);
void hdb_handle_destroy (
struct hdb_handle_database *handle_database,
unsigned long long handle);
void hdb_iterator_reset (
struct hdb_handle_database
*handle_database);
void hdb_iterator_next (
struct hdb_handle_database *handle_database,
void **instance,
unsigned long long *handle);
Figure 6: The Handle Database API Definition
Corosync Library API
Corosync Library API(如图7中所定义)提供了与Corosync服务引擎通信的机制。 库可以使用cslib_service_connect()与Corosync Cluster Engine连接。 此函数返回两个文件描述符。 一个文件描述符用于请求和响应消息。 剩余的文件描述符用于不应阻止正常请求的回调数据。
建立IPC连接后,可以使用cslib_send()发送请求消息。 可以使用cslib_recv()接收响应。 除非要接收的消息的大小是可变长度,否则通常不应使用这些函数。
当要接收的消息大小已知时,应使用cslib_send_recv()。 这将发送请求,并接收已知大小的响应。
所有这些功能都可以处理短读或写时消息传输的恢复,或者在可能发生信号或其他系统错误的情况下。
最后,轮询文件描述符很有用,尤其是在调度例程中。 这可以通过使用类似于poll系统调用的cslib_poll()来实现,除了它重试信号和其他可恢复的错误。
cslib_service_connect (
int *response_out,
int *callback_out,
unsigned int service);
cslib_send (int s,
const void *msg,
size_t len);
cslib_recv (int s,
const void *sg,
size_t len);
cslib_send_recv (
int s,
struct iovec *iov,
int iov_len,
void *response,
int response_len);
cslib_poll (
struct pollfd *ufds,
unsigned int nfds,
int timeout);
Figure 7: The Corosync Library API Definition
Service Engine Programming Model and Interface
overview
服务引擎由设计人员提供的插件接口和使用Corosync Cluster Engine API的功能实现相结合。 服务引擎设计者实现插件接口。 该接口是一组动态加载的函数和数据。 服务管理器指示服务引擎执行功能。 然后,一些服务引擎功能使用四个API,这些API在服务引擎中注册,以执行Corosync Cluster Engine的操作
Plug-In Interface
完整的插件接口是图8中所示的C结构。该接口包含数据和函数调用,服务管理器使用这些调用来引导服务引擎插件。
name字段包含唯一标识服务引擎名称的字符串。此字段由Corosync Cluster Engine打印,以向用户提供状态信息。
id字段包含在Corosync Cluster Engine中注册的16位唯一标识符。此唯一标识符用于由服务管理器将库和图腾请求路由到适当的服务引擎。
当需要私有数据来存储状态信息时,进程间通信管理器在连接初始化期间分配参数private_data_size大小的内存块。
exec_init_fn字段是为初始化服务引擎而执行的函数。 exec_exit_fn字段是为请求服务引擎关闭而执行的函数。当管理员将SIGUSR2信号发送到Corosync Cluster Engine进程时,exec_dump_fn函数会将服务引擎的状态转储到日志记录系统。
lib_init_fn字段是在进程间通信管理器向服务引擎启动新库连接时执行的函数。 lib_exit_fn字段是进程间通信管理器关闭IPC连接时执行的函数。
服务引擎的主要功能由服务引擎使用lib_engine和exec_engine参数进行管理。这些参数包含由服务管理器执行的函数数组。
服务管理器将服务引擎连接路由到正确的lib_engine功能。当库连接请求服务引擎执行功能时,连接的id用于标识要执行的数组中的函数。lib_engine_count包含lib_engine数组中的条目数。
然后,该函数通常使用corosync_api_v1结构中可用的各种API来创建计时器,发送Totem消息或使用进程间通信管理器响应消息。
当Totem消息发起时,服务管理器将它们传递给适当的exec_engine函数给集群中的每个处理器。根据函数头中的服务id调用正确的exec_engine函数。 exec_engine_count包含exec_engine数组中的条目数。
服务引擎的设计应该通过在exec_engine函数中执行服务引擎的大部分逻辑来利用Totem排序保证。这些函数通常使用进程间通信管理器API响应发起Totem消息的库请求。
struct corosync_lib_handler {
void (*lib_handler_fn) (void *conn, void *msg);
int response_size;
int response_id;
enum corosync_flow_control flow_control;
};
struct corosync_exec_handler {
void (*exec_handler_fn) (void *msg, unsigned int nodeid);
void (*exec_endian_convert_fn) (void *msg);
};
struct corosync_service_engine {
char *name;
unsigned short id;
unsigned int private_data_size;
enum corosync_flow_control flow_control;
int (*exec_init_fn) (struct objdb_iface_ver0 *, struct corosync_api_v1 *);
int (*exec_exit_fn) (struct objdb_iface_ver0 *);
void (*exec_dump_fn) (void);
int (*lib_init_fn) (void *conn);
int (*lib_exit_fn) (void *conn);
struct corosync_lib_handler *lib_engine;
int lib_service_count;
struct corosync_exec_handler *exec_engine;
int (*config_init_fn) (struct objdb_iface_ver0 *);
int exec_service_count;
void (*confchg_fn) (
enum totem_configuration_type configuration_type,
unsigned int *member_list, int member_list_entries,
unsigned int *left_list, int left_list_entries,
unsigned int *joined_list, int joined_list_entries,
struct memb_ring_id *ring_id);
void (*sync_init) (void);
int (*sync_process) (void);
void (*sync_activate) (void);
void (*sync_abort) (void);
};
struct corosync_service_handler_iface_ver0 {
struct corosync_service_handler *(*corosync_get_service_handler_ver0) (void);
};
Figure 8: The Service Engine Plug-In Interface
Service Engine APIs
Overview
Corosync服务引擎API中有四组功能,如图9所示。
typedef void *corosync_timer_handle;
struct corosync_api_v1 {
int (*timer_add_duration) (
unsigned long long nanoseconds_in_future,
void *data, void (*timer_nf) (void *data),
corosync_api_handle_t *handle);
int (*timer_add_absolute) (
unsigned long long nanoseconds_from_epoch,
void *data, void (*timer_fn) (void *data),
corosync_timer_handle_t *handle)
void (*timer_delete) (corosync_timer_handle_t timer_handle);
unsigned long long (*timer_time_get) (void);
void (*ipc_source_set) (mar_message_source_t *source, void *conn);
int (*ipc_source_is_local) (mar_message_source_t *source);
void *(*ipc_private_data_get) (void *conn);
int (*ipc_response_send) (void *conn, void *msg, int mlen);
int (*ipc_dispatch_send) (void *conn, void *msg, int mlen);
void (*ipc_refcnt_inc) (void *conn);
void (*ipc_refcnt_dec) (void *conn);
void (*ipc_fc_create) (
void *conn, unsigned int service, char *id, int id_len,
void (*flow_control_state_set_fn)
(void *context, enum corosync_flow_control_state flow_control_state_set),
void *context);
void (*ipc_fc_destroy) (void *conn, unsigned int service, unsigned char *id, int id_len);
void (*ipc_fc_inc) (void *conn);
void (*ipc_fc_dec) (void *conn);
unsigned int (*totem_nodeid_get) (void);
unsigned int (*totem_ring_reenable) (void);
unsigned int (*totem_mcast) (struct iovec *iovec, int iov_len, unsigned int gaurantee);
unsigned void (*error_memory_failure) (void);
};
Figure 9: The Service Engine APIs
Timer API
计时器api允许在计时器到期时执行用户指定的回调。 定时器可以被定义为绝对定时器,也可以定义为将来的某个持续时间。
timer_add_duration()函数用于添加一个回调函数,该函数将在未来的某个纳秒内到期。 timer_add_absolute()函数用于通过自纪元以来的纳秒数指定的绝对时间执行回调。
如果计时器已添加到系统中,并且稍后需要在计时器到期之前删除,则设计人员可以执行timer_delete()函数来删除计时器。
最后,服务引擎可以通过timer_get()函数调用获得自纪元以来纳秒的系统时间。
Interprocess Communication Manager API
进程间通信管理器API包括用于设置和确定消息源,获取IPC连接的专用数据存储以及将响应发送到响应或调度套接字描述符的功能。消息将根据消息头中的参数自动传递到正确的服务引擎。
ipc_source_set()将设置mar_message_source_t消息结构,其中包含节点标识和IPC连接的唯一标识符。服务引擎使用此功能来唯一标识IPC请求的来源。稍后,此mar_message_source_t结构将通过Totem以多播消息发送。一旦传递了此消息,Totem消息处理程序就可以通过确定消息是否通过ipc_source_is_local()在本地发送来响应ipc请求。
每个IPC连接都包含一个专用于IPC连接的专用数据区。该存储区域在IPC初始化时分配,并由服务引擎定义中的private_data字段确定。为了获取私有数据,函数ipc_private_data_get()函数由服务引擎设计者执行。
每个IPC连接实际上是两个套接字描述符。一个称为响应描述符的描述符用于对库用户的请求和响应。这些请求旨在阻止使用Corosync群集引擎的第三方进程,直到传递响应。如果第三方进程不希望阻塞行为,但可能希望在分派函数中执行回调,则服务引擎设计者可以使用ipc_dispatch_send()代替。
还有其他API可用于管理流量控制,但在简短的文章中解释起来很复杂。如果设计人员想要使用这些API,则应考虑查看Corosync Cluster Engine Wiki或邮件列表。
Totem API
Totem API非常简单,服务引擎只能使用三个API函数。这些函数获取当前节点ID,允许重新启用失败的环,并允许组播消息。相反,Totem的大部分复杂性都与Corosync服务引擎接口相连,并且对用户隐藏。
要获取当前的32位节点标识符,可以调用函数totem_nodeid_get()函数。在比较哪个节点为服务引擎发起消息时,这很有用。
当Totem配置为冗余环操作模式时,活动环可能会失败。发生这种情况时,服务引擎可以通过管理操作执行totem_ring_reenable()来修复失败的冗余环。
服务引擎通过发送多播消息然后基于多播消息参数执行某些功能来完成大部分工作。要组播消息,通过totem_mcast()API发送io向量。然后根据扩展的虚拟同步模型将此消息传递到所有节点。
Miscellaneous APIs
目前,Corosync群集引擎中的许多子系统都能够容忍分配内存的失败。 此规则的例外可能是服务引擎实现本身。 当在服务引擎中发生不可恢复的内存分配故障时,将调用api error_memory_failure()以通知Corosync集群引擎调用该函数的服务引擎存在内存故障。
将来,Corosync Cluster Engine设计人员打算管理服务引擎的内存池,以避免任何内存不足或内存进程不足。
Security Model
Corosync Cluster Engine可以缓解以下威胁:
- 伪造的图腾消息旨在使Corosync集群引擎出错
- 监控网络数据以捕获敏感的群集信息
- 来自非特权用户的错误IPC消息旨在使Corosync Cluster Engine出现故障
Corosync群集引擎通过两种机制缓解这些威胁: Totem消息和IPC用户的认证 使用加密的Totem消息的保密性
Integration with Third Party Projects
OpenAIS
OpenAIS [OpenAIS]是服务可用性论坛的应用程序接口规范的实现。 该规范是一种C API,旨在通过减少冗余修复的平均时间来提高可用性。 与OpenAIS集成是一项简单的任务,因为大多数Corosync功能都是从OpenAIS代码库中减少的。 当OpenAIS被分成两个项目时,插件使用的一些内部接口发生了变化。 这些内部API的使用被修改为本文中描述的定义
OpenClovis
OpenClovis [OpenClovis]是服务可用性论坛的应用程序接口规范的实现。 OpenClovis使用Corosync服务的某些部分。 具体来说,它使用Totem协议API为其Cluster Membership API提供成员资格。
OCFS2
OCFS2 [OCFS2]文件系统可以使用关闭的进程组api来传递有关已安装集群的各种状态信息。 此外,由于封闭的进程组服务的虚拟同步功能,CPG服务用于支持Posix锁定。
Pacemaker
Pacemaker [Pacemaker]是一个可扩展的高可用性集群资源管理器,以前属于Heartbeat [LinuxHA]的一部分。 Pacemaker于2005年7月首次作为Heartbeat-2.0.0的一部分发布,克服了Heartbeat之前集群资源管理器的不足之处
- 最多2个节点
- 高度耦合的设计和实施
- 过于简单的基于组的资源模型
- 无法检测资源级故障并从中恢复
- Pacemaker现在独立于Heartbeat进行维护,以便同等地支持OpenAIS和Heartbeat集群堆栈。
Pacemaker功能被分解为逻辑上不同的部分,每个部分都是一个独立的过程,并且能够独立于其他部分进行重写/替换:
- cib-群集信息库的缩写。 包含所有群集选项,节点,资源,它们之间的关系以及当前状态的定义。 将更新同步到所有群集节点。
- lrmd-本地资源管理守护程序的缩写。 非群集感知守护程序,它提供支持的资源类型的公共接口。 直接与资源代理(脚本)交互。
- pengine-政策引擎的缩写。 根据当前状态和配置计算集群的下一个状态。 生成包含操作和依赖项列表的转换图。
- tengine-过渡引擎的缩写。 协调策略引擎生成的转换图的执行。
- crmd-群集资源管理守护程序的缩写。 主要是PE,TE和LRM的消息代理。 同时选举领导者来协调集群的活动。
当与使用插件/服务引擎扩展其功能的Corosync集成时,每个功能一个进程的Pacemaker设计提出了一个有趣的挑战。 为了简化移植到Corosync Cluster Engine的任务,创建了一个小插件来提供Heartbeat传统上提供的服务。 一个 启动时,Pacemaker服务引擎会产生Pacemaker进程并在发生故障时重新生成它们。 支持群集的组件使用进程间通信管理器连接到插件。 然后,这些应用程序可以发送和接收群集消息,查询当前成员资格信息以及接收更新。 Pacemaker组件通过非正式API间接使用Pacemaker服务引擎功能,该API用于隐藏所选集群堆栈的详细信息。 抽象层可以自动确定操作堆栈,并通过检查运行时环境在运行时选择正确的实现。 一旦Pacemaker服务引擎和抽象层发挥作用,Pacemaker就会独立于堆栈,如图10所示,只需很少的努力。
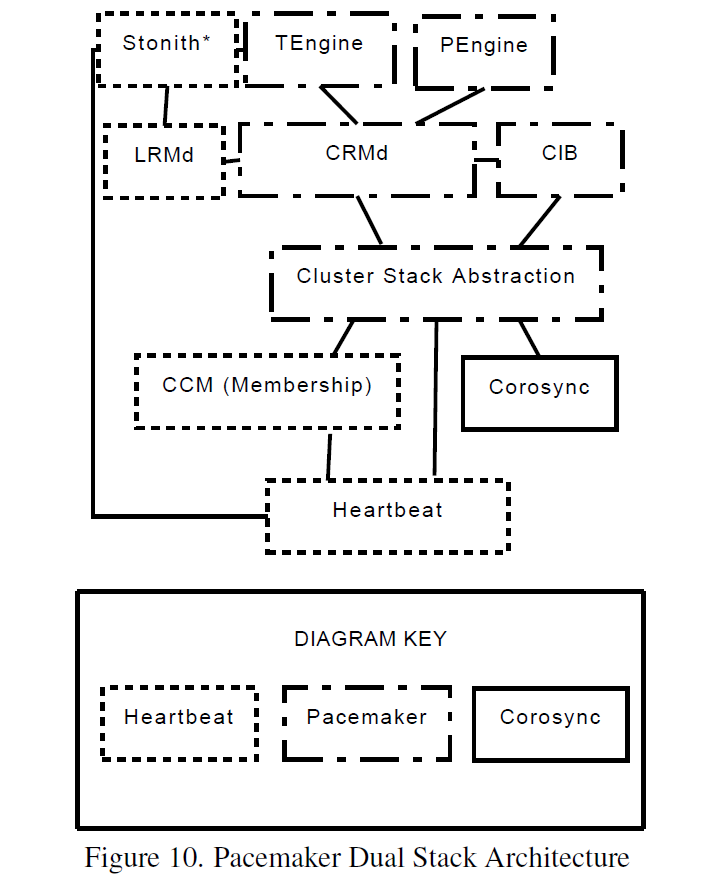
Pacemaker组件交换主要由压缩的XML格式字符串组成的消息。 将有效负载表示为XML并不高效,但格式的冗长意味着它压缩得很好,复杂的对象很容易被许多自定义和标准库解包。 为了适应Pacemaker,Corosync集群引擎设计人员增加了有序的服务引擎关闭。 当管理员或其他服务引擎触发关闭Corosync Cluster Engine时,服务引擎会清理并正常退出。 这允许Pacemaker服务引擎组织节点上的资源,以便在Corosync服务引擎进程退出之前正常迁移并最终停止其子进程。
Red Hat Cluster Suite
Red Hat Cluster Suite [RHCS]版本3使用Corosync Cluster Engine。 Red Hat Cluster Suite使用名为CMAN的服务引擎为其他Red Hat Cluster Suite服务提供服务。 Quorum是CMAN服务的主要功能,并且是所有Red Hat Cluster Suite软件堆栈的强大依赖。 Quorum确保群集运行一致,超过一半的节点可以运行。没有仲裁,诸如全局文件系统之类的文件系统可能导致数据损坏。 仲裁磁盘软件通过API与CMAN服务通信。仲裁磁盘软件提供额外的投票信息,以帮助基础架构识别满足特殊条件的仲裁时间。 Red Hat Cluster Suite使用名为CCS的分布式基于XML的配置系统。 CMAN提供了一个配置引擎,可以读取Red Hat Cluster Suite特定的配置格式文件并将它们存储在对象数据库中。此配置插件会覆盖/ etc / corosync / corosync.conf配置文件格式的默认解析。 libcman库提供了与Red Hat Enterprise Linux 4中的cman-kernel的向后兼容性。这种向后兼容性被一些应用程序使用,例如CCS,CLVMD和rgmanager。 Red Hat Cluster Suite,更具体地说是全局文件系统组件,使用在Corosync Cluster Engine中包含的CPG接口内标准化的Closed Process Groups接口。
Future Work
Corosync集群引擎团队打算提高引擎的可扩展性。 目前,该引擎已用于物理60节点集群。 该引擎已在128节点虚拟化环境中进行了测试。 虽然这些环境证明Corosync集群引擎能够在大量处理器数量下正常工作,但该团队希望将可扩展性提高到更大的处理器数量并减少延迟,同时提高吞吐量。 Corosync集群引擎设计人员希望添加一个通用的仲裁插件引擎,以便任何项目都可以定义自己的仲裁系统。 最后,团队希望为多个插件服务添加通用防护引擎和机制,以确定如何协作阻止
Conclusion
本文介绍了使用Corosync Cluster Engine的强有力的理由,并证明该设计通常适用于各种第三方集群项目。 本文还介绍了当前的体系结构和插件开发人员应用程序编程接口。 最后,本文简要介绍了我们未来的一些工作。